FSL-SAGE: Accelerating Federated Split Learning via Smashed Activation Gradient Estimation
Published in ICML 2025:
As models grow ever larger (e.g. modern neural nets and foundation models), traditional federated learning (FL) begins to strain client devices that lack the memory or compute capacity to host full models. Split learning (SL) offers one workaround by splitting the model between client and server — but it often introduces significant latency and communication overhead because the server must serially assist each client’s training step. Prior hybrid approaches that embed local “auxiliary” losses let clients train in parallel, but they lose server feedback and risk accuracy degradation. The key tension: how to balance client resource constraints, parallel training, and fidelity to the server’s learning objective.
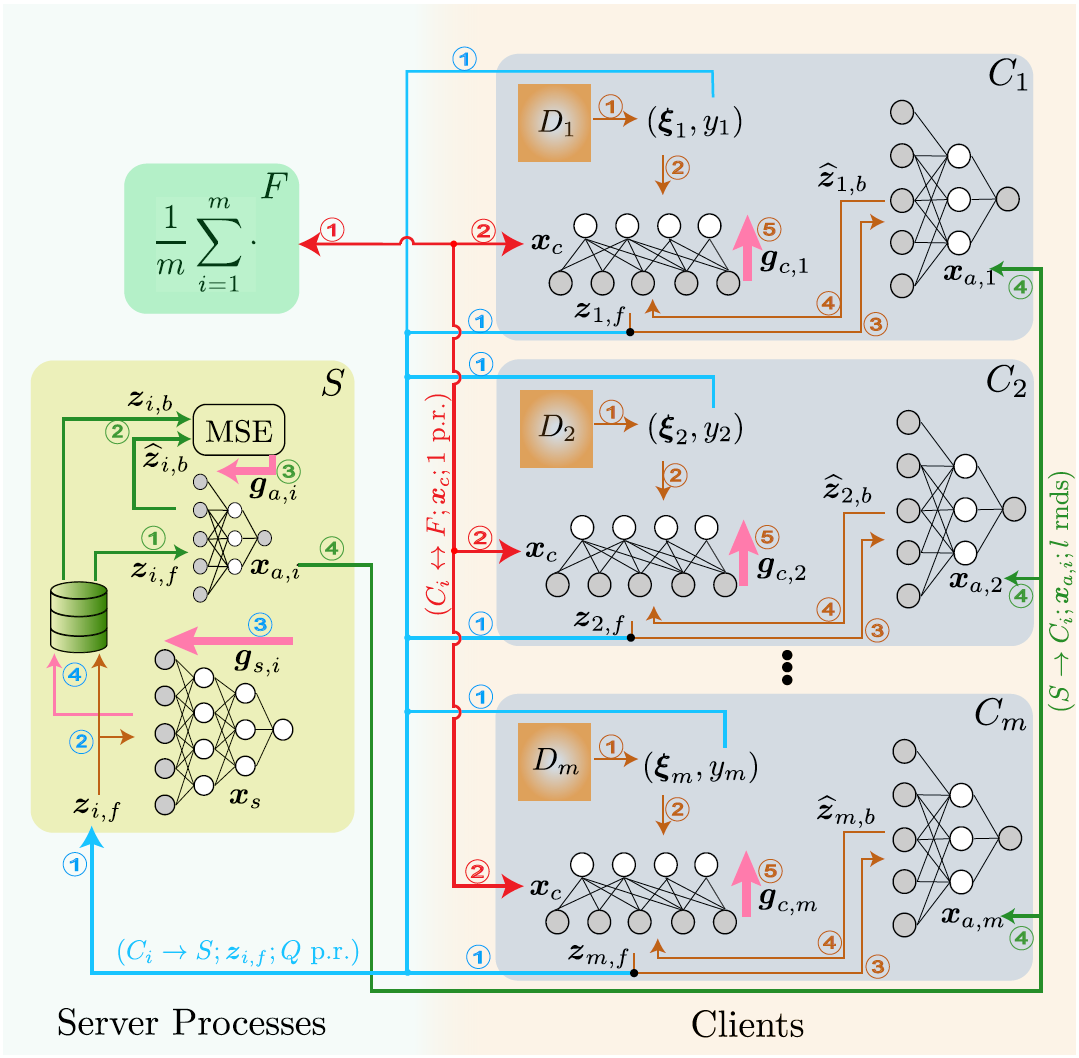
We introduce FSL-SAGE (Federated Split Learning via Smashed Activation Gradient Estimation), a new algorithm that retains parallelism like FL but splits the model like SL. Each client holds a client-side model plus a small auxiliary model. The auxiliary model is trained to estimate the server-side gradient feedback — i.e., it approximates how the server would respond to the client’s “cut-layer” activations. The client uses that estimate to update its parameters, without waiting for the server to compute and send back gradients each round. Periodically, the auxiliary model is realigned (retrained) using real server feedback to stay in sync. This design introduces multiple time scales (client updates, server updates, auxiliary alignment), which complicates convergence analysis.
Theoretically, FSL-SAGE achieves a stationary convergence rate of \( \mathcal{O}(1/\sqrt{T}) \) for \(T\) rounds, matching classical FL bounds despite its split structure — a nontrivial result given the estimation errors introduced by auxiliary models. Empirically, the method outperforms state-of-the-art federated split methods in both communication efficiency and accuracy on benchmark tasks (e.g. ResNet-18, GPT2-medium) (openreview.net). In effect, FSL-SAGE offers a practical route toward scalable, privacy-preserving training of large models on edge devices: reducing client load, accelerating convergence, and preserving performance across heterogeneous clients.